library(tidyverse)
library(RColorBrewer)
library(patchwork)
library(glue)
library(tidymodels)
library(kknn)
library(themis)
library(vip)
library(rpart)
library(rpart.plot)Analyse et prédiction de la santé mentale d’adolescents
Importation des librairies
Création des fonctions
# Fonction servant à afficher les variables numériques
graph_num = function(nom_var,couleur = "skyblue"){
# 1. Calcul des valeurs au dixième près
moy_val <- mean(data[[nom_var]])
med_val <- median(data[[nom_var]])
# 2. Création des labels avec les valeurs
label_moy <- glue("Moyenne : {sprintf('%.1f',moy_val)}")
label_med <- glue("Médiane : {sprintf('%.1f',med_val)}")
# 3. Graphique
ggplot(data, aes(x = .data[[nom_var]])) +
geom_histogram(fill = couleur, color = "white",binwidth = 0.5) +
# On mappe la couleur à un identifiant textuel ("moy" et "med")
geom_vline(aes(xintercept = moy_val, color = "moy"), linewidth = 1, linetype = 2) +
geom_vline(aes(xintercept = med_val, color = "med"), linewidth = 1, linetype = 3) +
# On utilise scale_color_discrete en spécifiant les labels calculés
scale_color_manual(labels = c("med" = label_med, "moy" = label_moy),
values = c("med" = "blue", "moy" = "red")) +
theme_classic() +
theme(
legend.position = c(0.98, 0.98),
legend.justification = c("right", "top"),
legend.text = element_text(size = 10), # Texte très petit
legend.title = element_blank(), # Supprime le titre "Légende"
legend.key.size = unit(0.3, "cm"), # Réduit la taille des traits/symboles
legend.background = element_rect(fill = alpha("white", 0.5)) # Transparence
) +
labs(title = NULL)
}
# Fonction servant à afficher les variables qualitatives
graph_qual = function(nom_var,couleur = "skyblue"){
data_graph =
data %>%
group_by(.data[[nom_var]]) %>%
summarise(n = n()) %>%
ungroup() %>%
mutate(pourcent = sprintf("%.2f",n/sum(n)*100),
texte = glue("{n} ({pourcent}%)"))
ggplot(data = data_graph, aes(x = .data[[nom_var]], y = n)) +
geom_bar(fill = couleur,
stat = "identity") +
geom_text(aes(label = texte),
vjust = -0.5) +
theme_classic() +
labs(title = NULL)
}Importation du document et présentation de la base
data =
read.csv("Teen_Mental_Health_Dataset.csv") %>%
as_tibble()
glimpse(data)Rows: 1,200
Columns: 13
$ age <int> 14, 19, 17, 15, 15, 19, 18, 16, 19, 15, 16, 1…
$ gender <chr> "male", "female", "female", "male", "female",…
$ daily_social_media_hours <dbl> 7.9, 1.9, 1.3, 7.4, 4.7, 7.4, 2.5, 4.0, 3.3, …
$ platform_usage <chr> "Instagram", "TikTok", "Instagram", "TikTok",…
$ sleep_hours <dbl> 7.4, 8.0, 7.6, 6.9, 4.9, 4.4, 6.4, 4.2, 5.0, …
$ screen_time_before_sleep <dbl> 2.9, 2.9, 0.5, 1.6, 3.0, 2.4, 2.4, 0.5, 2.1, …
$ academic_performance <dbl> 3.01, 3.22, 3.92, 3.48, 2.37, 2.63, 2.63, 2.4…
$ physical_activity <dbl> 1.5, 0.8, 0.0, 0.8, 1.4, 0.6, 0.7, 1.3, 0.9, …
$ social_interaction_level <chr> "low", "high", "high", "medium", "medium", "h…
$ stress_level <int> 2, 8, 2, 1, 3, 3, 2, 6, 1, 1, 5, 1, 5, 1, 1, …
$ anxiety_level <int> 2, 1, 4, 7, 5, 5, 2, 10, 10, 1, 8, 10, 7, 10,…
$ addiction_level <int> 1, 10, 2, 9, 2, 7, 5, 5, 9, 4, 9, 8, 6, 10, 1…
$ depression_label <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …Comme on peut le voir dans les données, les variables : gender, platform_usage, social_interaction_level, depression_label (la variable cible) ne sont pas au bon format. Je commence donc par les mettre en facteur.
data =
data %>%
mutate(across(any_of(c("gender", "platform_usage","social_interaction_level")), as.factor)) %>%
# On depression_label transforme en facteur car on va faire de la classification ET on définit "1" comme le premier niveau (c'est par défaur le premier niveau de facteur que la métrique est calculée avec tidymodels)
mutate(depression_label = factor(depression_label, levels = c("1", "0")))On commence par observer la distribution de la variable cible : depression_label
data %>%
group_by(depression_label) %>%
summarise(n = n()) %>%
ungroup() %>%
mutate(pourcent = sprintf("%.2f",n/sum(n)*100),
texte = glue("{n} ({pourcent}%)")) %>%
ggplot(data = .,aes(y = n, x = depression_label)) +
geom_bar(fill = "skyblue",
stat = "identity") +
geom_text(aes(label = texte)) +
theme_classic() +
labs(title = NULL)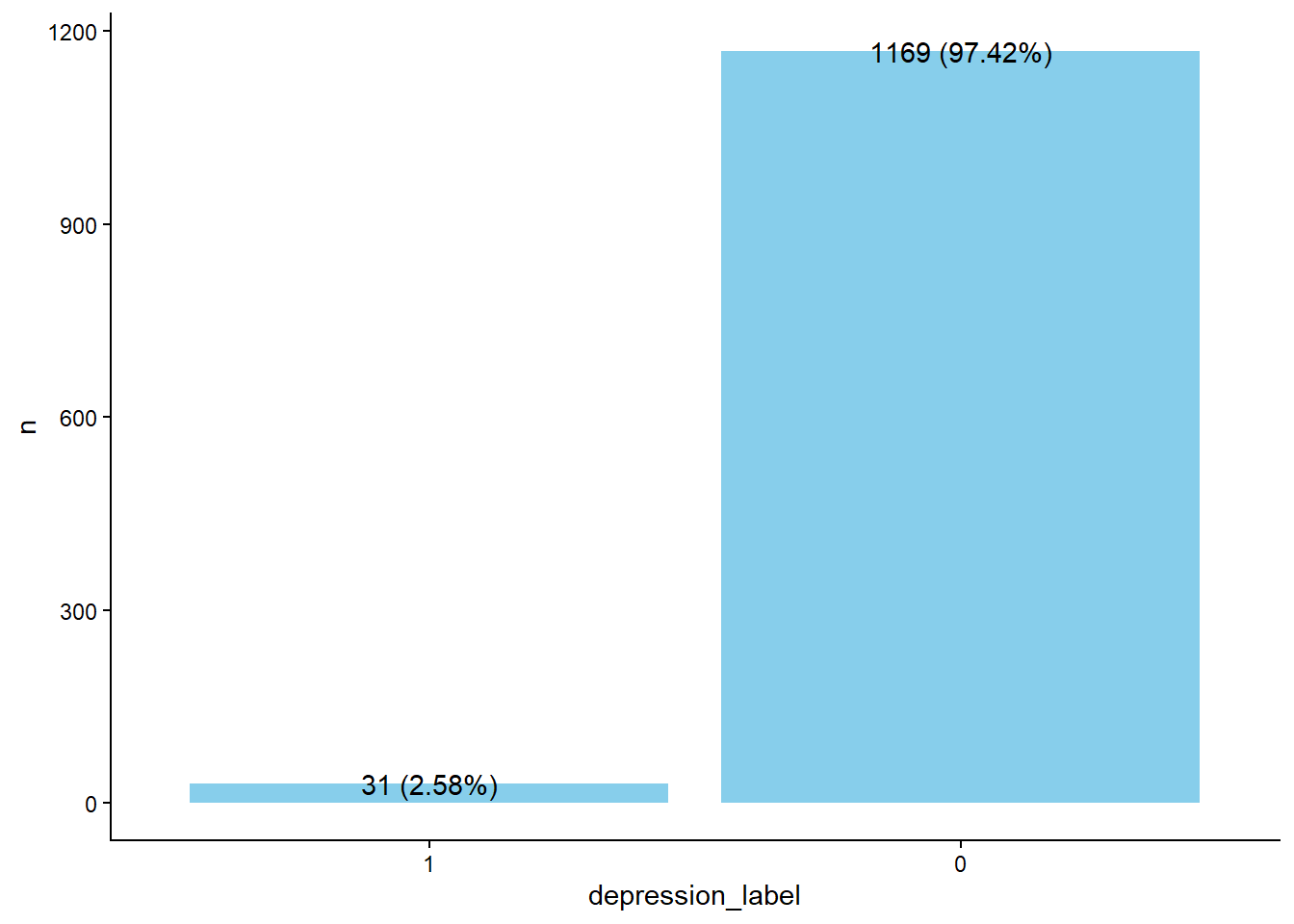
Comme on peut le voir, elle est fortement déséquilibrée. Il faudra donc en tenir compte dans les analyses.
J’affiche maintenant chaque variable qualitative pour voir visuellement sa distribution.
cols_qualitatives =
data %>%
select(where(is.factor),-depression_label) %>%
colnames()
mes_couleurs = brewer.pal(n = length(cols_qualitatives), name = "Set3")
list_graph = purrr::map2(cols_qualitatives, mes_couleurs, ~graph_qual(.x, .y))
wrap_plots(list_graph, ncol = 3)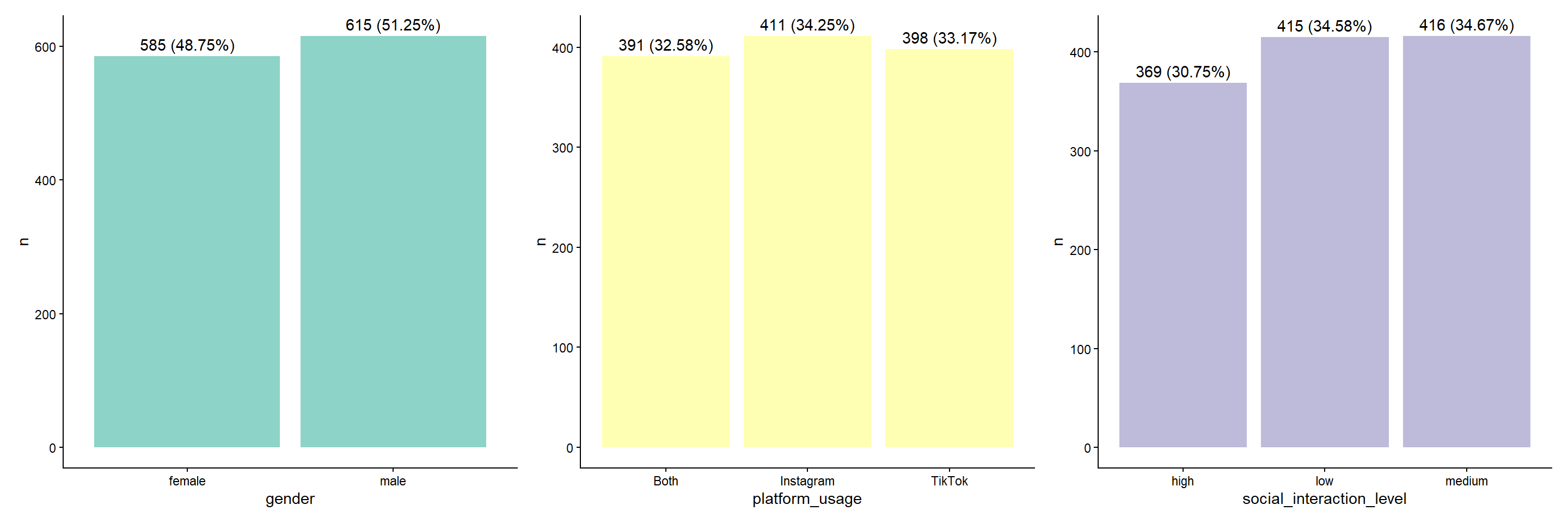
La variables social_interaction_level semble ordonnée. Il serait donc plus correct de la passer en numérique pour tenir compte de cette information. On la transforme donc.
data =
data %>%
mutate(social_interaction_level = case_when(social_interaction_level == "high" ~ 2,
social_interaction_level == "medium" ~ 1,
social_interaction_level == "low" ~ 0,
TRUE ~ NA_integer_))Puis on observe maintenant les variables quantitatives :
cols_numeriques =
data %>%
select(where(is.numeric),-depression_label) %>%
colnames()
mes_couleurs = brewer.pal(n = length(cols_numeriques), name = "Set3")
list_graph = purrr::map2(cols_numeriques, mes_couleurs, ~graph_num(.x, .y))
wrap_plots(list_graph, ncol = 3)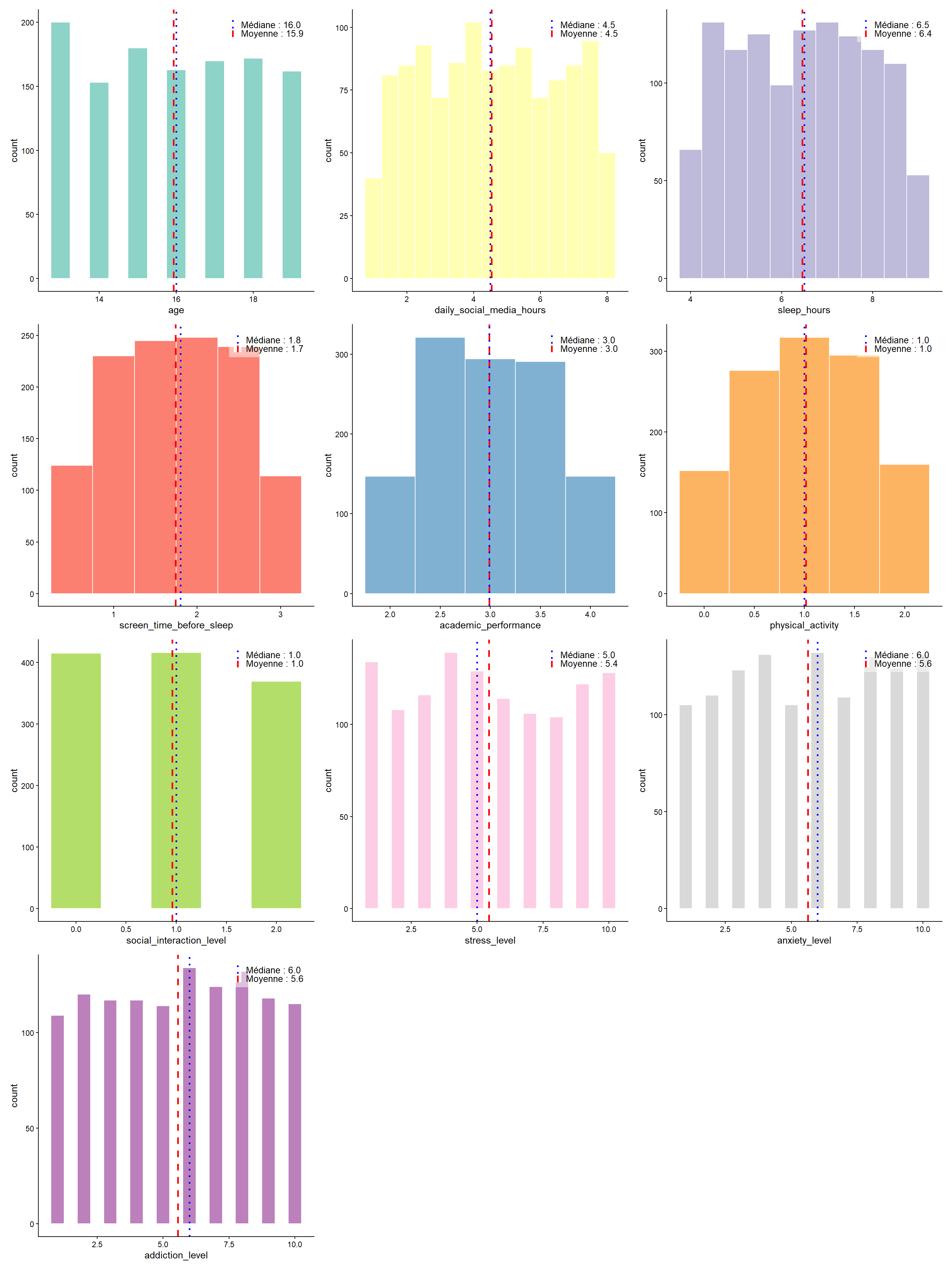
Séparation des données test/train
On sépare les données de façon à avoir 70% de données d’apprentissage et 30% de données test. Je m’assure d’avoir des observations de la classe sous-représentée de la variable depression_label dans les données test/apprentissage avec l’argument strata. Ce n’est pas forcément le cas si on ne fait pas de stratifications étant donné que les données sont très déséquilibrées.
set.seed(04052026)
data_split <- initial_split(data, prop = 0.7,strata = depression_label,pool = 0.01)
dapp = training(data_split)
dtest = testing(data_split)On observe maintenant la repartition de la variable cible entre les deux jeux de données.
graph_app =
dapp %>%
group_by(depression_label) %>%
summarise(n = n()) %>%
ungroup() %>%
mutate(pourcent = sprintf("%.2f",n/sum(n)*100),
texte = glue("{n} ({pourcent}%)")) %>%
ggplot(data = .,aes(y = n, x = depression_label)) +
geom_bar(fill = "skyblue",
stat = "identity") +
geom_text(aes(label = texte)) +
theme_classic() +
labs(title = "Données d'apprentissage")
graph_test =
dtest %>%
group_by(depression_label) %>%
summarise(n = n()) %>%
ungroup() %>%
mutate(pourcent = sprintf("%.2f",n/sum(n)*100),
texte = glue("{n} ({pourcent}%)")) %>%
ggplot(data = .,aes(y = n, x = depression_label)) +
geom_bar(fill = "skyblue",
stat = "identity") +
geom_text(aes(label = texte)) +
theme_classic() +
labs(title = "Données de test")
wrap_plots(c(graph_app,graph_test), ncol = 2)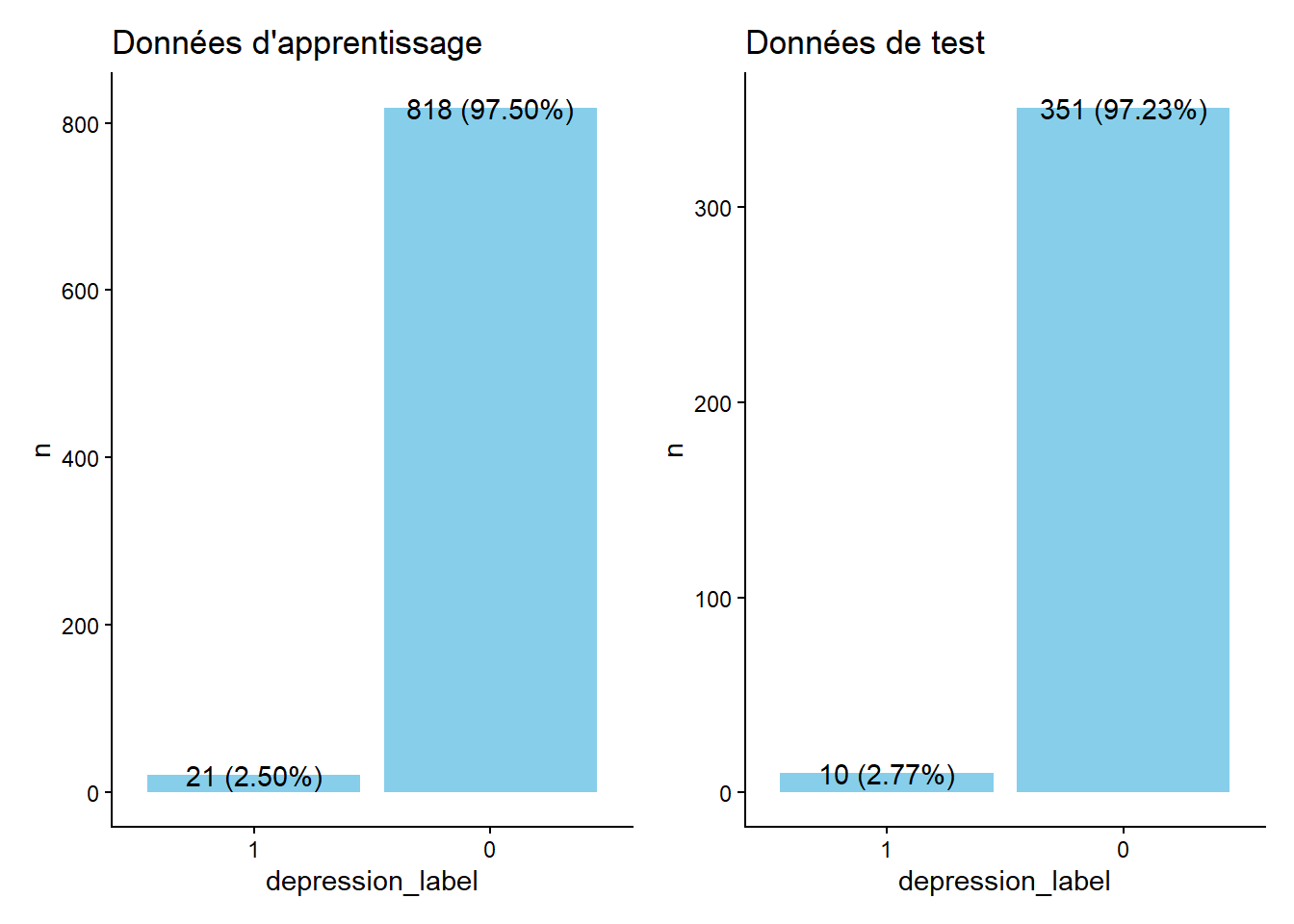
Sur-échantillonnage
Il s’agit maintenant de s’occuper du déséquilibre des données. Comme l’une des catégories de la variable cible ne comporte que 21 occurences dans les données d’apprentissages, il n’est pas envisageable de réaliser un sous-échantillonnage pour entrainer le modèle : on se retrouverait alors avec uniquement 42 observations ce qui représenterait une perte énorme d’information. C’est la raison pour laquelle j’ai choisi de partir sur un sur-échantillonnage.
Comme on veut que les données test soient le plus proche possible de la réalité, elles ne seront pas modifier pour évaluer les modèles.
Critère de performance
Comme les données sont déséquilibrées, la précision qui est le critère de performance classique n’est ici pas adapté. Si on le choisissait, le modèle prédirait simplement 0 à chaque fois et aurait une précision excellente puisque ce serait vrai dans 97.5% des cas. Il faut donc des critères qui prennent en compte cette problématique.
Le rappel est ici l’indicateur tout indiqué : son calcul se concentre sur la capacité du modèle à identifier correctement tous les individus de la classe d’intérêt qui est ici très minoritaire. Dans un contexte de santé mentale, le poids des Faux Négatifs est bien plus important que celui des Faux Positifs, car l’enjeu est de ne manquer aucun adolescent en détresse, même au prix d’une précision légèrement moindre.
Pour compléter l’analyse, j’ai aussi décider d’utiliser le F1-score qui est une moyenne harmonique entre le rappel et la précision.
KNN
Ce modèle simple est une méthode “naïve” pour prédire la dépression. Il nous servira de modèle de référence pour comparer plus tard des modèles plus complexes.
knn_spec <-
nearest_neighbor(
neighbors = tune(), # On renseignera plus tard la grille des paramètres
weight_func = tune()) %>% # On choisit arbitrairement la distance euclidienne
set_engine("kknn") %>%
set_mode("classification")Il est nécessaire de normaliser les données : comme la distance euclidienne est utilisée, une variable pourrait avoir plus d’impact qu’une autre juste en raison de son échelle. On transforme également les variables qualitatives en dummy pour pouvoir les introduire dans le modèle.
knn_recipe <- recipe(depression_label ~ ., data = dapp) %>%
# On gère les variables nominales
step_dummy(all_nominal_predictors()) %>%
# On normalise toutes les variables explicatives (moyenne 0, écart-type 1)
step_normalize(all_predictors())Comme expliqué précédemment, il est préférable de réaliser une stratégie de sur-échantillonnage. J’ai décidé de la réaliser avec l’algorithme SMOTE. Cette étape doit arriver impérativement après la normalisation des données pour ne pas center/réduire les variables sur des données artificielles, ce qui rajouterait du bruit à l’information. De plus, la distance euclidienne utilisée dans SMOTE serait elle aussi inadaptée compte tenu de la différence d’échelle entre les variables.
knn_recipe =
knn_recipe %>%
step_smote(depression_label,over_ratio = 1) # On veut autant de 0 que de 1 dans depression_labelEnfin on créé le workflow
knn_workflow <- workflow() %>%
add_recipe(knn_recipe) %>%
add_model(knn_spec)Pour entrainer le modèle et choisir les meilleurs paramètres tout en évitant au maximum l’écueil du sur-apprentissage, on fait une validation croisée en 10-blocs.
La validation croisée est ici particulière car il y a du sur-échantillonnage à réaliser. Hors, il ne faut pas absolument pas réaliser la validation croisée sur toutes les données ré-échantillonnées car on aurait alors une sur-représentation des observations de la classe minoritaire et le risque de sur-apprentissage serait bien trop important. C’est très bien expliqué dans cet article rédigé par Damien martin.
Sur les 10 blocs de la validation croisée, les 9 blocs d’apprentisages seront donc systématiquement sur-échantillonnées pour avoir le meme nombre d’observation des classes 0 et 1 de depression_label. Le dernier bloc de test restera quant à lui tel quel. La bonne nouvelle est que toutes ces étapes sont implicitement réalisées dans tidymodels.
re_ech_cv = vfold_cv(dapp,v=10,strata = depression_label,pool = 0.01)Warning: Stratifying groups that make up 1% of the data may be statistically risky.
ℹ Consider increasing `pool` to at least 0.1.On créé la grille des paramètres que l’on veut tester.
grille_k = crossing(neighbors=1:100,
weight_func = c("gaussian","biweight"))On détermine les critères de performance que l’on veut utiliser.
class_metrics = metric_set(recall,f_meas)Enfin on estime le risque pour chaque valeur de la grille grâce à la validation croisée.
knn.cv <- knn_workflow %>%
tune_grid(
resamples = re_ech_cv,
grid = grille_k,
metrics=class_metrics)→ A | warning: While computing binary `precision()`, no predicted events were detected (i.e.
`true_positive + false_positive = 0`).
Precision is undefined in this case, and `NA` will be returned.
Note that 3 true event(s) actually occurred for the problematic event level, 1There were issues with some computations A: x8
There were issues with some computations A: x8On visualise les erreurs
tbl <- knn.cv %>% collect_metrics()
ggplot(tbl, aes(x=neighbors,y=mean,colour = .metric,linetype = weight_func)) +
geom_line()+
labs(colour = "Mesure",
linetype = "Distance",
x = "Nombre de voisins",
y = "Score") +
theme_bw()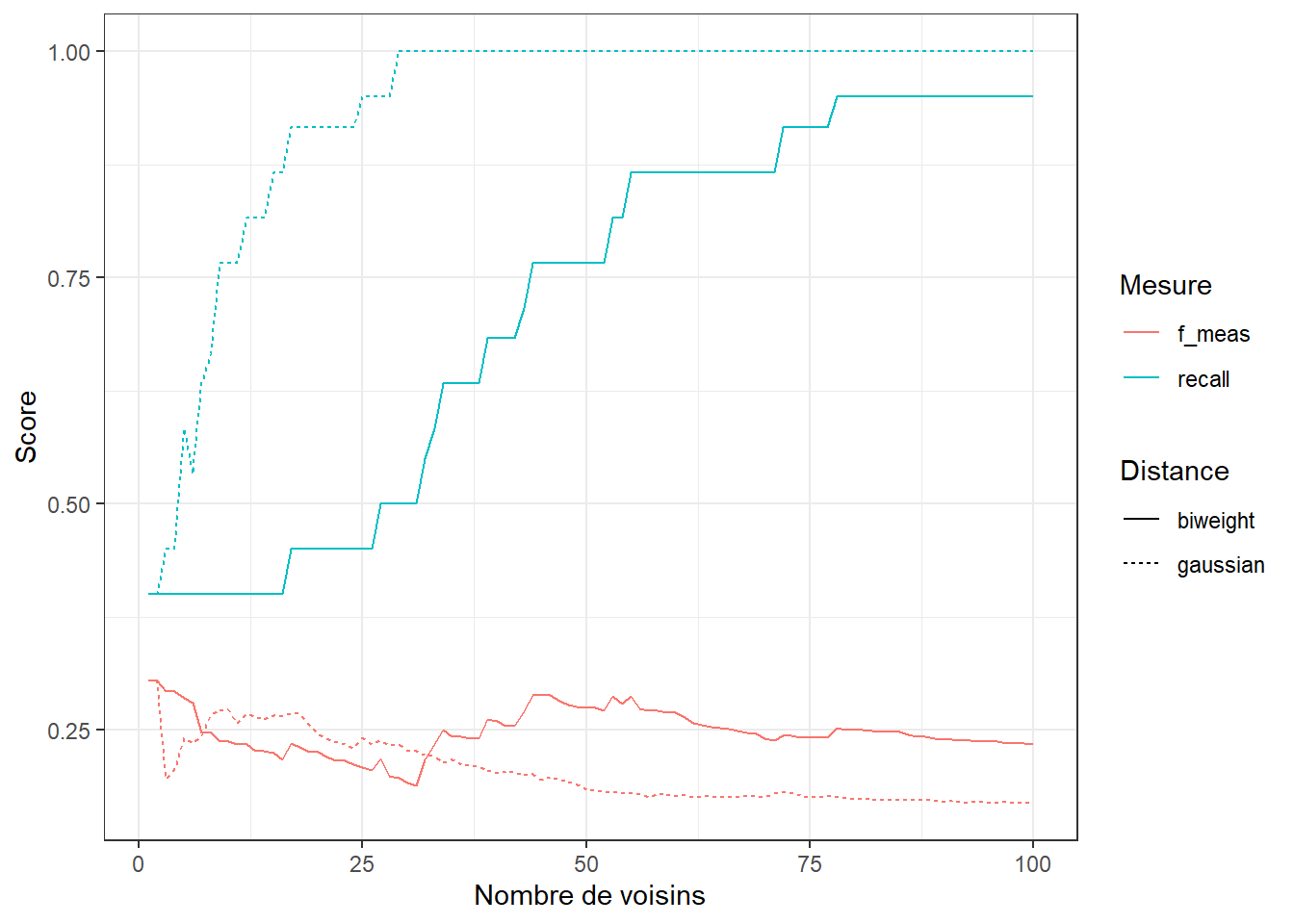
On observe ici un résulat intéressant : le modèle excèle quand le nombre de voisin est réduit mais est très mauvais plus ce nombre augmente. Quand j’ai vu ce résultat ma première réaction a été de me dire que le modèle sur-apprenait ou qu’une erreur s’était glissé dans mon raisonnement ou mon code. Mais en réfléchissant je me suis rendu compte que c’était en fait très logique. Comme la variable d’intérêt qu’on cherche à prédire est très déséquilibrée, si le nombre de voisin était trop important alors il prédirait toujours 0 car il aurait statistiquement beaucoup plus de chance de tomber sur un voisin prédisant 0. C’est donc ici logique que le modèle soit plus performant avec un nombre de voisin très faible.
On affiche les meilleurs résulats
knn.cv %>% show_best(metric = "recall") %>% select(1:6)# A tibble: 5 × 6
neighbors weight_func .metric .estimator mean n
<int> <chr> <chr> <chr> <dbl> <int>
1 29 gaussian recall binary 1 10
2 30 gaussian recall binary 1 10
3 31 gaussian recall binary 1 10
4 32 gaussian recall binary 1 10
5 33 gaussian recall binary 1 10knn.cv %>% show_best(metric = "f_meas") %>% select(1:6)# A tibble: 5 × 6
neighbors weight_func .metric .estimator mean n
<int> <chr> <chr> <chr> <dbl> <int>
1 1 biweight f_meas binary 0.304 9
2 1 gaussian f_meas binary 0.304 9
3 2 biweight f_meas binary 0.304 9
4 2 gaussian f_meas binary 0.304 9
5 3 biweight f_meas binary 0.293 9Dans les deux cas, que ce soit pour le rappel ou le F1-score, le modèle est optimal quand le nombre de voisin est égal à 1 (soit le plus petit possible).
On l’applique alors l’ensemble des données d’apprentissage
best_k = knn.cv %>% select_best(metric = "f_meas")
final_knn =
knn_workflow %>%
finalize_workflow(best_k) %>%
fit(data = dapp)On peut maintenant voir la performance finale de notre modèle sur les données de test
# Prédictions
resultats_test =
dtest %>%
bind_cols(predict(final_knn, dtest)) %>%
bind_cols(predict(final_knn, dtest, type = "prob"))
# Matrice de confusion
resultats_test %>%
conf_mat(truth = depression_label, estimate = .pred_class) Truth
Prediction 1 0
1 7 19
0 3 332# performance
resultats_test %>%
class_metrics(truth = depression_label, estimate = .pred_class)# A tibble: 2 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 recall binary 0.7
2 f_meas binary 0.389Arbre de décision CART
On regarde maintenant avec un arbre de décision CART quelle serait la performance.
set.seed(42)
tree_spec <-
decision_tree(
cost_complexity = 0,
tree_depth =5,
min_n = 50) %>%
set_engine("rpart",
control = rpart.control(
minbucket = 35, # Equivalent exact de min_samples_leaf
xval = 0 # On désactive la validation croisée interne de rpart
)) %>%
set_mode("classification")
tree_recipe <- recipe(depression_label ~ ., data = dapp) %>%
# On gère les variables nominales
step_dummy(all_nominal_predictors()) %>%
step_smote(depression_label,over_ratio = 1) # On veut autant de 0 que de 1 dans depression_label
tree_workflow <- workflow() %>%
add_recipe(tree_recipe) %>%
add_model(tree_spec)
# grille_k = tibble(neighbors=1:100)
#
# knn.cv <- knn_workflow %>%
# tune_grid(
# resamples = re_ech_cv,
# grid = grille_k,
# metrics=class_metrics)
tree_fit <- tree_workflow %>%
fit(data = dapp)
tree_fit %>% extract_fit_engine %>% rpart.plotWarning: Cannot retrieve the data used to build the model (model.frame: objet '..y' introuvable).
To silence this warning:
Call rpart.plot with roundint=FALSE,
or rebuild the rpart model with model=TRUE.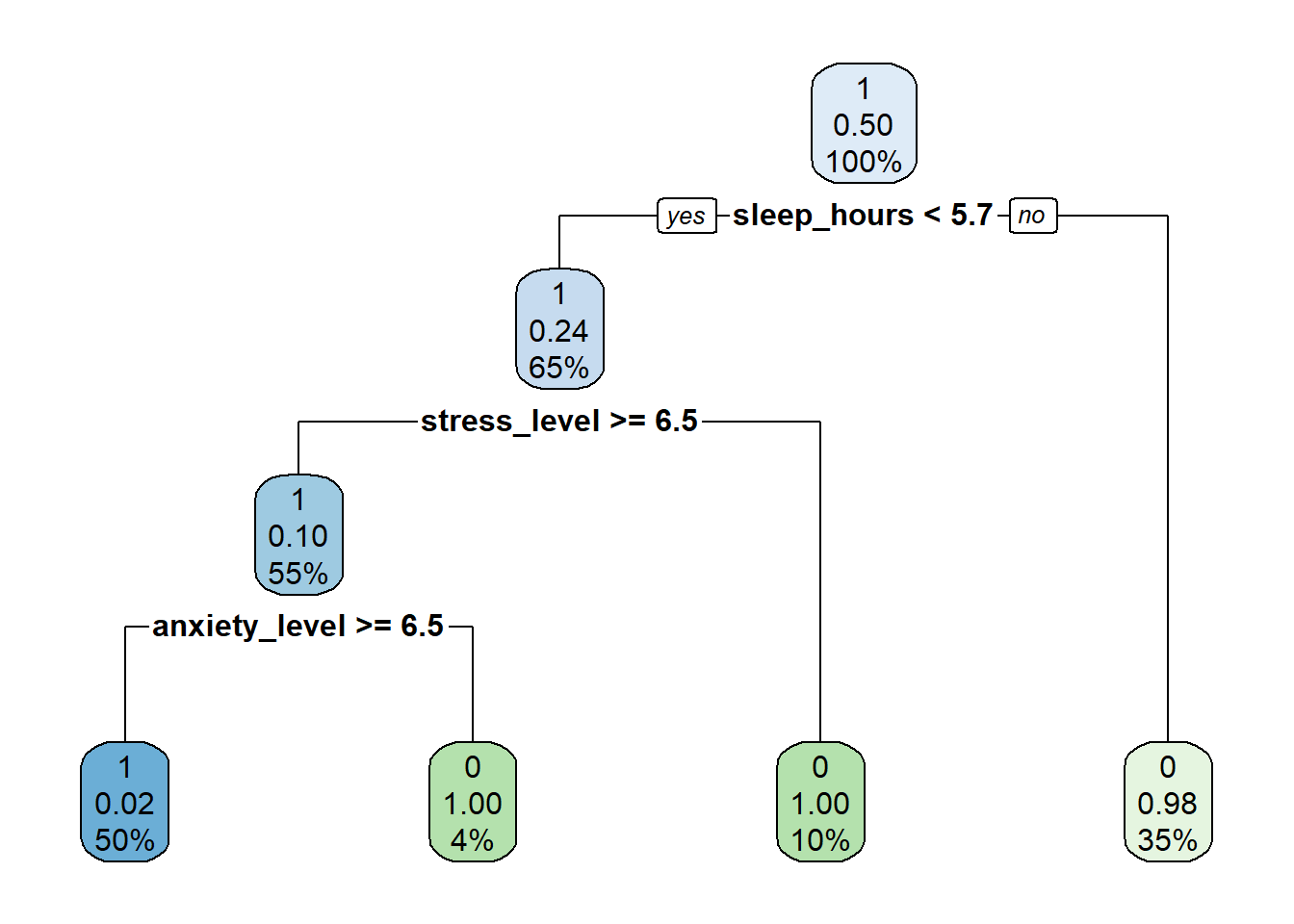
# Prédictions
res_tree =
dtest %>%
bind_cols(predict(tree_fit, dtest)) %>%
bind_cols(predict(tree_fit, dtest, type = "prob"))
# Matrice de confusion
res_tree %>%
conf_mat(truth = depression_label, estimate = .pred_class) Truth
Prediction 1 0
1 8 14
0 2 337# performance
res_tree %>%
class_metrics(truth = depression_label, estimate = .pred_class)# A tibble: 2 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 recall binary 0.8
2 f_meas binary 0.5